
Sora来了,中国能否赶上与美国AI的差距?
作者:猫哥
本文由公众号猫哥的视界(ID:maogeshijue)授权转载。
最近,OpenAI突然发布首款文生视频模型—Sora。
很多人试用之后感叹:AI视频要变天了!
Sora不仅能够根据文字指令,创造出宏大、精美且颇具想象力的作品,运镜角度也能达到大师的水平。
而且,它的制作长度达到了1分钟,比现在最好的Runway Gen 2、Pika等AI视频工具的几秒视频强了几倍。

说实话,这本来应该是只有影视行业在意的事情,但万万没想到,国内又开始有人反思了。
有人说这意味着第N次的工业革命又被欧美人开启了,有人说面对算力芯片的封锁中国的国运又要再次沉沦,还有人引申吐槽国内的科研人员都在琢磨人际关系,搞不出来这种颠覆性的成果来。
那么,Sora到底是个啥?到底厉害在哪里?在AI领域,中美真正的差异在哪里?
1Sora的原理和厉害之处
其实吧,别看现在写Sora的文章满天飞,原理机理头头是道,还有人开始趁机卖Sora的课程乃至变现课程了,但绝大部分不靠谱。
为啥?
因为Sora根本没公测呢!
OpenAI公布的,只是Sora发布的几个视频,而且至今没对公众开放Sora的测试权限。
事实上,OpenAI公开表示,为了保证Sora的安全性,需要经过红队安全测试之后再考虑面向公众开放。
所谓“红队”可以理解为模拟黑客团队,目前只招收居住在美国的人,也就是说,国内用户现在连内测的机会都没有。
而就在2月15日,OpenAI官网首次列出中国、俄罗斯、伊朗、朝鲜几个所谓国家附属行为AI威胁参与者,并终止相关OpenAI账户。
连测试还没有测试,甚至连测试的资格都没有,咱们网上那些课程和解读是哪来的?
可想而知。
目前,唯一可以一探Sora奥秘的渠道,就是OpenAI官网关于Sora背后的技术理论的简介。
内容比较抽象,一般人看不懂,不过Sora的技术来源之一的Transformer的作者、上海交大天才少年、纽约大学助理教授谢赛宁啃完了OpenAI附件的32篇的论文,对内容做出了分析,也许我们可以一探究竟。
Sora最大的创新,是在论文中,提出了一个SpaceTime latent patch的概念。
你可以把它理解为一个“时空图像块”,每个“时空图像块”就相当于语言模型的token。
Sora的原理,就是通过你的提示词,提取关键字,比如主题、动作、地点、时间和情绪。
再从它的数据集里搜索与关键字匹配的、最合适的时空图像块。
然后按照数据集中其他时空图像块的之间逻辑,猜测自己的下一个时空图像块是什么。
最后通过LDM的建模方法+DiT的模型结构的生成能力,在时间轴上生成了一个连续的视频。
Sora最强大的能力,其实就在这一点上:
它不是通过单帧画面想象的,而是通过一个个时空图像块,然后来构成整个场景。
所以它天然适合生成连贯的视频,而且这个视频还能保持一致性、一惯性(比如人物的衣服不会发生变化)。

咱们通俗地打个不是十分贴切的比方。
你让Sora给你做个《三体》的视频,它要在数据集中先读一遍三体,然后给每一个角色,都建立了一个故事线。
谁和谁在一起,做了什么,然后所有角色和情节构成了很多网。
这样他就能通过网上交织的这一个个的时空图像块,按照你的提示词来构成整个画面。
哪怕你的提示词是“秦始皇和叶文洁共进晚餐”这样离谱的内容,他也能给你生成出来。
所以,Sora的最大优势,就是这种虚拟的架构能力。
就像《盗梦空间》里面的筑梦师,可以根据自己的想法,快速生成出一个世界。
当然,这个世界只是看起来像真的,现实世界中的一些物理规律比如重力、比如各种材料的强度等等,Sora无法模拟。
所以哪怕OpenAI发布的视频中,也有不少Bug。
比如随着时间推移,有的人物、动物或物品会消失、变形或者生出分身;
或者出现一些违背物理常识的闹鬼画面,像穿过篮筐的篮球、悬浮移动的椅子等等。

尽管如此,也不能否认Sora的巨大意义。
Sora的最大的意义,在于其对数据集中的时空图像块的逻辑进行了理解,然后能对其发展规律进行分析,然后给出你想要的画面。
虽然现在Sora的最大作用是生成视频,可能颠覆掉整个影视行业。
但问题在于,这种算法,完全可以移植到其他依据“画面”做出判断的行业中去。
“画面”是物理世界的影像,我们做出的一切活动或者行动,都是依据眼睛看到的“画面”而做出的。
那么一旦AI具备了根据“画面”做出自主判断的能力,是不是其他行业也会被颠覆?
比如俄乌战场上漫天飞的无人机,现在还需要人来遥控,未来会不会就有无人机根据画面中敌军的活动进行自主攻击了?
比如现在的智驾虽然已经非常发达,但多用来跑高速,在城市复杂的交通环境下还是力有不逮。
但如果Sora移植到智驾上去,就可能真正让AI学会自己开车,再复杂的路况也不在话下。
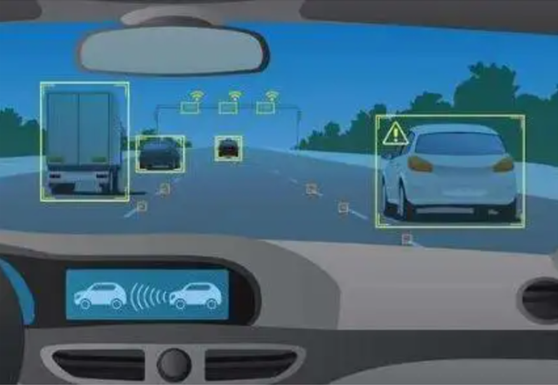
还有制造业,现在虽然智能制造已经流行,但所有机械臂都必须按照限定的位置、限定的轨迹、限定的力度去运转。
如果Sora移植到智能制造上去,机械臂就能像人一样,根据不同的情况,做出不同的安排了。
你以为业内大佬恐惧的是Sora做视频么?
不,业内大佬真正恐惧的,是Sora这种算法,在所有行业的铺开!
2中美在AI领域的差距
了解了Sora的厉害之处,我们不禁感叹,这次技术突破,又被美国人抢先了。
这当然不是因为某些自媒体说的“外国人比中国人创造性强”,而是因为中美在AI领域的基础本来就有差距。
从目前看,AI三大基础,数据、算力、算法,这三大基础,中国一个都不占优势。
第一是数据。
用过GPT的人都知道,虽然GPT可以做出中文回答,但是呢?
GPT的回答,总是干巴巴,很枯燥,就像是用翻译软件直接把英语翻译过来一样。
其实情况也差不多,GPT是以英语训练的,只不过给你的回答翻译成了中文而已。
为啥要用英语呢?
很简单,英语的训练数据集足够大。
虽然世界上有十几亿人使用中文,但我们不得不承认,虽然世界只有七八亿人说英语,但使用英语的接近20多亿人。
这20多亿人每天都在产生大量的英文数据,无论是报刊杂志,还是官方网站,或是在网上发布的推特,用的都是英语。
就连国内最关键的各种学术论文,有相当多也要翻译成英语,在国外杂志上发表或者上传到arXiv。
这就让英语在作为训练语言时,拥有了足够大的数据量,这是GPT诞生在美国的天然优势。
所以GPT在训练中,用来训练的主流数据集以英文为主,如Common Crawl、BooksCorpus、WiKipedia、ROOT等。
最流行的Common Crawl中文数据虽然在总量上排名第二,但只占据4.8%。
中文数据集有没有呢?
也有,比如MSRA-NER、Weibo-NER,以及CMRC2019、ExpMRC2022等,但整体数量和英文数据集相比差距巨大。
而且相对老旧,特别是缺乏前沿学术论文平台(比如韩国超导论文上传的arXiv)的数据。
这就导致国内做大模型的团队面临了一个尴尬的局面。
用中文数据集吧?
数据量太小,训练不出足够智能的AI。
要想达到效果,还不如用英文数据集来训练,然后套个翻译器来凑合用。
用英文数据集吧?
训练出的大模型始终是英文思维,当遇到一些中文语言特色的内容或者各种俗语、隐喻以及暗示时,往往处理不佳。
如果单纯的聊天,理解错了可能没问题,但如果拿来工业使用,问题可就大了。
第二是算力。
在总算力上,美国占全球的34%,中国占33%,差距很小,两者构成绝对的第一梯队。
在智能算力上,中国占全球的45%,美国占28%,中国在规模上绝对领先。
目前智算中心20个,在建智算中心20个,是美国的一倍多。
中国总算力略低的主要原因就是计算芯片有差距,单位算力低于美国。
中国和美国在处理器CPU芯片上有差距。
大家都知道,比如自从美国禁止超算用CPU出口中国之后,中国超算再也没进过世界前十,让美国彻底赢得了这场超算竞赛的胜利。
中国最快的超算“神威·太湖之光”性能,只相当于排行榜第一名美国Frontier的十分之一,落后明显。

但更大的差距,在GPU。
GPU芯片和CPU芯片不太一样。
以 CPU 提供算力,适合复杂逻辑运算,比如大多数通用软件。
70% 以上晶体管用于构建 Cache 和控制单元,计算核心从几个到几十个。
GPU就不一样了,它适合逻辑简单,计算密集型高的并发任务。
70% 以上晶体管用于构建计算单元,计算核心几千或上万个,适合量大但简单的运算。
AI计算崛起之后,人们发现,GPU似乎天生是为AI计算而生的。
AI大模型在参数规模上得到大幅提升,一般达到千亿甚至万亿规模,这就导致出现了海量的并行计算需求。
GPU可以通过并行处理大量的计算任务,从而大幅提高计算速度和效率,可大幅缩短AI算法的训练和推理时间,成为AI时代的算力核心。
GPU对AI的提升是革命性的。
2010年的时候,AI先驱吴恩达为了让AI程序识别出一只猫,使用了16000个CPU。
但后来吴恩达换用GPU去识别一只猫,只需要12颗GPU。
所以,GPU对AI来说至关重要,可以说,谁掌握GPU,谁就掌握AI的未来。
令人遗憾的是,如今GPU霸权,掌握在美国人手里。
当年英伟达不去抢英特尔CPU的生意,而是死磕GPU,最终形成了英伟达全球显卡市场上的霸主地位。
因为英伟达在GPU计算卡领域入局早,早早地建立起软件标准护城河。
如今只要你算AI,都要用英伟达的计算卡,无论是讯飞大模型,还是百度的文心一言,还是小鹏的自动驾驶,底层都离不开英伟达GPU。

但是这样一来,就给了美国卡脖子的机会。
2023年8月31日,美国政府命令芯片厂商英伟达停止向中国销售A100、H100系列芯片,禁止AMD向中国销售MI100、MI200系列芯片,这都是用于AI计算的主流芯片。
这样一来,英伟达可就哭了,中国那么大的市场,好好的钱不让赚,你让我咋办?
于是英伟达为了赚钱的同时还不违反美国出口限制规定,针对中国市场推出了阉割版的特供版芯片 ——A800/H800(处理速度约为A100/H100的70%)。
虽然保留了强大的计算能力,但训练AI大模型的时间将增加。
不过即便如此,A800/H800也是中国能得到的最好的AI芯片。
然后在2023年10月17日,美国商务部工业和安全局(BIS)更新了“先进计算芯片和半导体制造设备出口管制规则”。
更严格的控制了英伟达A800和H800芯片,还更新了限制标准,增加了“性能密度”标准,阻止企业寻找变通方案。
然后英伟达老老实实遵从禁令,对算力和内存进行“再次阉割”,推出了H20,L20,L2等新版替代芯片特供中国市场。
但性能只有H100、A100系列的20%,国内各大厂商测试之后,觉得这玩意已经没啥采购价值了。
这样一来,就相当于在AI这场赛跑中,美国人穿碳板跑鞋在跑,而中国人只能穿解放鞋跑。
先天就不公平,落后也就非常正常了。
第三是算法。
在产业界有句话,美国人擅长从0到1,中国人擅长从1到10。
这句话,放在AI领域也完全成立。
美国非常重视AI的基础研究理论创新,相关顶级论文数量,数倍于中国。
特别是GPT诞生后,各种资金砸进了AI领域,大量人才进入AI行业,这才导致了AI的各种算法的大爆发。
这次Sora的胜利,其实就是思路和算法的胜利。
中国呢?
中国的AI行业(其实不仅仅是AI行业)往往是先从市场需求产品需求开始,有需求了再慢慢投入科学家和基础研究,再结合市场需求,带动基础研究落地。
但这样一来,如果不去进行基础研究,那很难产生从0到1的创新突破。
AI的行业又不像传统的行业可以利用数量优势转化为竞争优势,几乎每一次算法革新,带来的都是颠覆性的革命(就好比Sora颠覆Pika一样)。
你落后一步,后续的无数步就别想跟上了,这场竞赛还怎么搞?
当然,除此之外,中国搞AI算法,还要考虑更多和AI无关的东西。
我们假设一下,假设一家投资公司,在中国投资AI企业,首先考虑的是什么?
不是基础研究,而是要用算法把数据集“净化”一下,去掉各类有害信息。
毕竟在中国,企业的“道德要求”非常高(参见理想车机回答钓鱼岛和台湾事件)。
企业如果不对AI提供的负面信息进行规避,那么就要承担相应的责任,甚至在舆论漩涡中面临生死选择。
这样一来,当数据集先天有残缺的情况下,相比美国AI算法毫无禁忌地加速学习,掌握尽量多的网络信息,在训练效率上就先天有差距了。
当然,虽然中国在数据、算力和算法领域,都全面落后,但并不能就此说中国AI技术一定会全盘落后于美国。
为啥?
因为中国正在发挥自己的独有优势,迎头赶上。
国家印发了《数字中国建设整体布局规划》,明确“数据要素为数字中国建设战略中的关键一环。”
2024年2月19日,国务院国资委也召开“AI赋能 产业焕新”中央企业人工智能专题推进会,要求要夯实发展基础底座,把主要资源集中投入到最需要、最有优势的领域。
啥是基础底座?
自然是数据。
所以,各行各业都在拼命完善发布自己的数据集,弥补当前中文开源数据集的不足,而且供开源使用。
比如复旦大学发布的CodeGPT和中文语料图书集合CBook-150k,上海交大、香港理工大学等机构RefGPT,北京人工智能研究院、浙江大学、北京航空航天大学的“中国通用开放指令数据集”COIG,以及哈工大的中文医学指令数据集Huatuo等等。
阿里也开放了数千计公开数据集,还建设了可搜索、使用和打榜的天池数据集平台。
说实话,虽然英语数据量大,但要说其数据质量,真的不如中文。
中文训练内容中,有比较专业的内容平台,比如知乎,拥有超过 4300 万创作者产生的超过 3.5 亿条优质中文问答内容。
涉及政治,经济,文化,历史,科技等几乎全部门类,这种经过梳理的数据几乎先天适合AI训练。
还有微信公众号数据,背靠全民级应用,每年公众号文章数千亿字。
既有专业领域内容分析,也有时事热点分析,这些内容对语言模型的训练迭代有重要作用。
所以腾讯“混元”大模型特有的训练数据主要来自微信公众号,微信搜索等优质数据。
更不要说一些美国没有的B 端行业数据。
比如矿山,铁路、电商等行业数据,可以拿来做细分领域大模型精确训练的基础。
比如华为的盘古大模型,就是利用这些B端行业数据训练出的。
你让盘古陪你聊天可能够呛,但你让他给你分析高铁数据,绝对会比GPT强。
至于算力差距问题,我们也不用太过担心。
美国人似乎忘了,中国并不是一个靠封锁就能打垮的国家。
原子弹、氢弹、弹道导弹、隐身飞机、航母、大型驱逐舰、大型燃气轮机、盾构机等等等,哪个不是被封锁的?哪个又封锁住了?
几十年的历史证明,美国越封锁和打压,中国越重视,越投资源去发展。
根据IDC数据,预计2023年中国GPU市场规模将达到111亿美元,这是啥概念?
一个千亿级别的市场,被美国人的一纸禁令,给硬生生让出来了!
中国企业过去最怕的啥?
就怕在国际巨头的垄断下没有市场!
原来中国GPU为啥不行?
因为提起GPU大家第一个想到的就是英伟达和AMD。
毕竟人家是大品牌,性能成熟、优化好、适配好,用起来省事,所以你就算自己研发出来了,也没人用。
赔钱的买卖没人干,所以国产厂商都不愿意去花钱研发GPU。
但现在呢?
美国人自己把AI芯片禁了,但中国这边的需求又没减少反而增大了,这是多么大的一个市场?
所以,这千亿级别的市场,迟早要被中国企业完全吃掉。
2020年之前,中国本土GPU企业才三家左右,至今仅仅两三年时间,GPU企业已经增至20多家。
目前,中国GPU企业不仅开始崛起,而且都已近结出了累累硕果。
首屈一指就是华为,华为的技术实力,我们不用怀疑。
目前,华为已经形成基于鲲鹏的通用算力以及基于昇腾的智能算力的算力体系,涵盖从底层硬软件到上层应用。
而且已经在政府、金融、电信、交通、教育等关键行业实现大规模的应用落地。
2023年8月,也就是美国禁A100那个月,华为突然与百度签约,以4.5亿元的价格出售整整1600枚的昇腾910B AI芯片。
预计下一步,百度在训练端会开始采用华为的昇腾芯片,替代英伟达的V100和A100。

昇腾910B的性能,完全可以比肩英伟达A100。
这话不是我说的,而是AI巨头之一科大讯飞创始人刘庆峰说的。
他不仅称赞了昇腾910B的性能,还说“现在业内基本都按照国产芯片来规划算力,科大讯飞早就已经按照不购买美国芯片来布局未来。”
无独有偶,360集团创始人周鸿祎也在乌镇峰会上表示,公司采购了1000片左右华为AI芯片,比百度还早。
10月,华为又紧接着推出全新架构的昇腾AI计算集群——Atlas 900 SuperCluster,其核心计算力已经超越了英伟达GHX100,成为了打破美国AI算力垄断的最大希望。
虽然华为短期内显然无法撼动英伟达,但对于国内AI企业来说,已经是从0到1的突破了。
这就像当年中国原子弹试爆成功,美国的第一反应不是“他们造的不够先进”,而是“坏了,他们有原子弹了”。
更为可贵的是,中国GPU的崛起,不是一支独放,而是百花满园。
比如创业公司壁仞科技的BR104,还有摩尔线程的MTT S80,海光信息的深算二号DCU产品,其性能已经能够完整支持大模型训练。

2024年2月,一家英国媒体报导称,一家中国技术公司预计将于今年发布5nm制程的5G芯片,暗示中国已经突破了高制程的封锁。
现在在国产芯片制程落后的情况下,尚且能取得如此成绩,一旦芯片制程突破了5nm,那还不要起飞了?
所以,美国的制裁和封锁,达不到扼杀中国算力的目的。
相反,只会把算力之战被拉到关乎国运的新高度,逼中国以国家之力推动中国算力一次又一次冲击算力之巅。
就像摩尔线程创始人兼CEO张建中在被美国制裁后,发布的全员信中说的:“中国GPU不存在至暗时刻,只有星辰大海。”
至于算法的差异,同样也不用担心,因为中美在AI科技领域的应用,完全是两条路线。
3中美AI场景应用的差异
网上有句话,叫:美国人在虚拟世界一骑绝尘,中国在实体经济遥遥领先。
这句话形象地概括了中美关于AI科技的发展思路是完全不同的。
我们可以看一下现在中美的大模型异同。
先看看ChatGPT和盘古大模型。
ChatGPT能陪你聊天,盘古大模型则涵盖自然语言处理(NLP)、计算机视觉(CV)和科学计算(SC)三个领域,旨在为行业客户提供全场景人工智能解决方案。
再看看中美对AI用途的区别。
美国人用AI干什么?
ChatGPT用来帮学生写作业,Sora用来做视频,Microsoft Cortana根据用户的需求提供个性化的信息和服务,如安排日程、发送邮件、搜索文件等。
甚至美国极右翼社交平台还上了一个AI交互产品“希特勒陪聊”,你能模拟和希特勒对话,真的是让人哭笑不得。

中国的AI呢?
举几个例子就知道了。
海尔集团的智慧工厂项目。
已经利用AI技术和物联网技术实现了自动化生产、数据共享、资源整合等功能,提高了生产效率和灵活性。
上海浦东机场的AI安检系统。
利用AI技术和人脸识别技术,实现了快速安检和准确识别,提高了机场安检效率和旅客体验。
互联网医疗平台好大夫在线的AI智能导诊系统。
可以根据患者的症状和情况,智能推荐适合的医生和治疗方案,提高了医疗资源的利用和医疗服务的效率。
中国人民银行数字货币研究所开发的人民币数字货币DC/EP,利用AI技术,实现了数字货币的发行和交易。
就算美国人引以为傲的类似于Sora的图像生成AI,中国也早已实用化了。
深圳光利用AI算法给你画建筑设计图、施工图这样的企业,就有几百家!
纳了闷了,中国都用AI搞基建了,没人说颠覆,美国人的Sora做个小视频,怎么就一大堆人吵吵着颠覆啦颠覆啦?
为啥会如此?
其实是因为无论是智能制造、智慧城市还是智慧医疗、智慧金融,中国的AI都更偏重于B端,而不像美国的AI那样更偏重于C端。
这就导致普通公众对中国的AI比较陌生,而容易被美国的炒作所吸引。
中美关于AI的不同发展路线,主要是因为中美经济模式有很大不同。
中国经济,靠的是实业,所以中国人无论研究什么技术,都想着把它用上。
在这个导向之下,AI企业想赚钱,就必须面向行业。
当然,影视行业倒不是不能面向,主要是中国影视行业没有好莱坞那么发达,特效需求不像美国那么大。
所以影视行业对AI的产业应用并不那么迫切,导致中国人没往这方面努力。
美国呢?
美国经济已经彻底空心化,华尔街的资本更喜欢用金融资本方式赚钱。
对他们来说,炒作一下AI概念,在市场上割韭菜,倒是比开工厂赚钱快多了。
你看,这几年我们见到的元宇宙、区块链、虚拟币、Web3、阿尔法狗,每个概念出台的时候,都有一大波人炒作颠覆啦颠覆啦。
结果呢?
几年过去,谁还记得这些概念?
说白了,都是资本的游戏而已。
美国倒是想搞出个振兴实业的AI,比如好好更新一下美国老旧的铁路和电网系统。
但问题在于,美国有特高压输电系统的数据吗?
美国有最高时速400KM/h行驶时保持稳定的姿态控制吗?
没有啊!没有的话AI怎么训练?
所以兜兜转转,只能回到“概念圈钱”的路子上来。
包括这次,为什么这次OpenAI突然发布Sora?
很大一部分因素,在于OpenAI的创始人兼CEO萨姆·奥特曼正在筹集总计高达7万亿美元的资金。
7万亿美元什么概念?
2022财年,美国联邦政府的财政收入只有4.9万亿美元!
7万亿美元相当于美国一年半的财政收入!
奥特曼要干啥?
对此,黄仁勋在会上有些讽刺地回应称:“(7万亿美元)显然能买下所有的GPU。”
奥特曼显然知道不可能真的筹集7万亿美元,但通过自己的Sora在筹资过程中加把火,自己哪怕筹集不了7万亿,筹资7000亿也行啊!
那也是全球首富马斯克资产的2倍好么?
偏偏资本市场就吃这一套。
很多人不懂装懂,更多的人虽然懂但出于利益推波助澜,于是就出现了神奇的“神奇的Sora颠覆产品”舆论热炒。
哪怕这款产品还没有公布测试。
对于这种资本炒作,咱们看看就得了,没必要跟风。
中国需要AI,但中国需要的不是Sora这样的AI。
因为Sora解析不了战斗机风洞对飞行器设计的核心数据,更无法给出采矿机械在复杂地层中掘进的深度和速度,更无法推动实体经济发展。
这,就是中美AI最大的不同。
4心存希望,向阳而生
回到Sora,Sora到底像不像有些人吹的下一次工业革命呢?
其实吧,这话术,我们已经不是第一次听了。
当年出了VR,有人说是第四次工业革命。
区块链,是第五次工业革命。
元宇宙,是第六次工业革命。
ChatGPT,是第七次工业革命。
这次的Sora是下一次工业革命,那就是第八次了吧?
第一次和第二次人类都花了上百年到几百年时间,现在呢?
还没过几年呢,咱们见证几次工业革命了?
这工业革命也太简单,太频繁了吧?
说实话,Sora可能会对影视行业构成一定影响,但要说它是工业革命,确实夸张了。
原因很简单,工业革命意味着生产力的革命性进步。
Sora能带来生产力的进步么?
这个世界说到底,还是物质的,虚拟空间的进步能带来效率的提高,但已经无法再像蒸汽机取代人力畜力那样,带来颠覆性进步了。

至于那些美国一出个什么新概念,然后一帮所谓学术精英、网络大V,开始以各个匪夷所思的角度来解释这个概念。
一会说“我们不行啊,这个那个……”,一会反思“我们为什么没有?体质问题”,一会又哀叹“不行了,没法活了……”。
所以,现在网上天天大叫“Sora太可怕”的,有些是真的无知,有的是推波助澜借此打击我们的发展信心。
还有的,是想趁机卖课割你的韭菜而已。
事实上,看看整个世界,有能力和美国在AI领域PK的,除了中国,还有谁?
所以,在AI领域缩小与美国差距,乃至追上美国,只是时间问题。
这绝不是盲目乐观,我们看看未来的趋势就知道。
第一,随着中国在芯片与GPU突破,中国算力建设将很快大规模超过美国。
2023年12月6日,黄仁勋曾公开透露,中国市场占了英伟达总营收的20%。
注意,这20%,是美国推出禁令之后的比例,此前的比例还更大。
作为中国的显卡大户们,占据了英伟达1/5收入的中国科技公司,包括百度、阿巴、腾讯和字节等公司,正在开始减少英伟达芯片的订单量。
开始公司内部自研芯片,或者转向国内芯片制造商,其中就包括黄仁勋盖章确认的“强大竞争对手”的华为。
2024年2月9日,据国家知识产权局公告,华为正申请一项名为“一种图形处理方法及装置”的专利,这显然是华为推出GPU的信号。
可以看出,华为在突破麒麟芯片生产技术之后,似乎有一种“一通百通”的意思了。
那么下一代国产GPU将承担起国内AI训练的重任,再加上国内本来规模就很大的超算中心,中国的算力建设必将超越美国。
第二,随着中国算力建设突破,在AI领域将出现质变。
AI这个东西,说复杂也复杂,说简单也简单。
简单的原因在于,你只要把算力堆到一定程度,就成容易成功。
这是AI训练中的“涌现现象”决定的。
大模型的“涌现”能力是一种深度学习模型的自我组织和自适应能力。
在深度学习中,模型会自动学习特征并进行组合,而随着网络深度的增加,模型的特征表达能力也会越来越强,进而产生出更加复杂和智能的行为。
也就是说,也许我的算法不够好,也许我的思路不够创新,但只要我的算力足够大,训练次数不够多,在模型训练达到一定程度时,它就能表现出一些出乎意料的行为和能力。
这些行为和能力通常是在训练数据中没有直接出现过的,也就是所谓Sora之类的“颠覆式创新”。
假以时日,当中国各行各业都开始使用超算中心进行AI训练时,不知道啥时候就能冒出来一个颠覆式成果,彻底掀翻牌桌。
到时候,中国就不是现在跟着美国屁股后面追的状态了,而是并驾齐驱,看谁更能把AI覆盖到更多行业领域的状态了。
考虑到中国AI在实体经济领域的深度应用,毫无疑问,中国的AI大模型将百花齐放,远远超过美国。
所以,作为咱们普通人来说,面对AI时代的到来,没必要妄自菲薄。
最好的选择还是脚踏实地的做事情,别一惊一乍的,那样最容易当韭菜了。
相关文章
-

陈都灵一袭绿色抹胸长裙 站在柳树下宛若自然精灵
近日,陈都灵最新造型美照释出,她身着一袭绿色抹胸长裙,站在柳树下宛若自然精灵,神秘而又清新。...
2025-04-24 09:21:51 都灵站在抹胸 -

梁朝伟刘嘉玲周润发齐聚 为杜琪峰庆生掀起回忆杀
4月22日晚,刘嘉玲于社交账号上发布了与梁朝伟、周润发、张叔平等好友为杜琪峰庆生的合影,画面中众人笑容满面,多年情谊尽显。刘嘉玲周润发同框合影,刘嘉玲微卷的利落短发造型十分吸睛。...
2025-04-24 09:21:44 刘嘉玲梁朝伟杜琪 -

林心如就黄子佼事件强硬表态:对虐待及影片持有行为零容忍
台媒消息显示,林心如于近期就黄子佼藏匿未成年人性影像一事再度发声。她郑重表明立场,明确表示对虐待未成年人以及持有相关影像的行为绝无妥协余地。...
2025-04-24 09:21:41 强硬影片行为 -

-

董璇泳池旁喝椰子水好惬意 穿优雅礼裙身姿曼妙
近日,董璇在社交平台上晒出一组写真美照,并配文称:“提前在广州感受了夏日赛道。”照片中,她身着一袭优雅礼裙在游泳池旁喝椰子水,面露明媚笑容,十分惬意。...
2025-04-24 09:21:14 椰子泳池曼妙 -

-

形势比人强,特朗普关税战打不下去了!
原创: 后沙来源微信公众号:后沙已获转载授权昨天在短短不到6个小时之内,特朗普发动的关税战又变调了。北京时间0时左右,美国财政部长贝森特在摩根大通的闭门会议上,放风称,中美之间的高关税是不可持续的,预计会降温。预计什么,预料到中国的态度?自己信吗?1点左右,白宫发言人莱维特在新闻发布会上也表达了类似的态度。5点左右,特朗普亲自确认,针对中国进口商品的关税税率不会维持在当前水平(145%),“它会大幅下降,但也不会降至零,中国将对最终的关税税率非常满意”。特朗普还说了些肉麻的话,要和中国幸福地生活在一起(v...
2025-04-24 09:21:03 关税不下去了形势 -

-

怂是真认怂,事是真没完!
作者:码头整薯条的海鸥来源:码薯学人今天我们来聊聊服软的特朗普。在美国时间4月22号发生了4件事:特朗普公开说开始考虑降低对华关税税率(强调不是0);特朗普放出消息说中美贸易谈判进展顺利;特朗普表示无意解雇美联储主席鲍威尔,但是还是要求美联储降息;特朗普的财长贝森特在22号摩根大通的闭门投资会上明确表示中美贸易战不能长期持续。这4条消息合在一起,我们可以明确一点,特朗普在释放善意。但是,善意不代表胜利。果然,就在4月23日,美国媒体突然传出消息说中美芬太尼谈判陷入僵局。22号的宣传口径表明特朗普确实在认怂...
2025-04-24 09:21:01 怂是真认怂事是真 -

特朗普不想打关税战了,想和中国幸福地生活在一起!
原创: 一棵青木来源公众号:远方青木已获转载授权特朗普发动的关税战又进入新阶段了,以一种你想都不敢想的方式。4月23日,特朗普公开发言称对中国的145%关税太高了,自己很快会大幅度降低,但不会降低到零。特朗普还说,中国将对最终的关税税率非常满意,但他们必须跟美国达成协议。还有更离谱的,特朗普说:“我认为中国会很高兴,我们会幸福地生活在一起”。没错,真的是这么说的。中文翻译看起来非常肉麻,但原文其实更肉麻,特朗普使用的英文单词原文是“very happily”。不仅要在一起(live together),还...
2025-04-24 09:20:59 关税中国幸福



